狂甩特斯拉几亿光年,罗纳德・费希尔才是最被低估的天才科学家
资讯
2024-01-01
348
现代统计学之父
或许对于大部分读者而言,罗纳德・费希尔(Ronald Fisher)并不算出名,但有数理统计基础的读者会对他有所耳闻。费希尔信息量、费希尔z分布、费希尔变换(相关系数的定义)等等,都是他的创造。其实他的贡献远不止此现代统计学之父这一称号,是对他更为贴切的描述。
费希尔出生于1890年,活跃于20世纪初[2]。很多读者都知道,这个时代可以算是人才辈出、百家争鸣,各个学科都得到了突飞猛进的发展,牛顿伽利略那个少数人掌管科学界的情况早已如同过往云烟。下面这张号称科学界最牛合影的照片拍摄于1927年,也仅仅包含了当时全球三分之一左右的智囊[3]。

(解图:第五届索尔维会议,组织者为普朗克,但主要是哥本哈根学派和爱因斯坦等人关于量子物理的争端)
尽管费希尔的名声可能不及上面各路大牛,但至少在现代统计学界,他依然是执牛耳者。其实那个年代著名的统计学家也不少,为什么费希尔才是现代统计学之父呢?我们来看看和费希尔同时代并且齐名的几位统计学家的主要贡献:

再来看看费希尔(不包括本文开头的几项贡献):

(怀疑探索者按:胡子一剃我们就可以得出结论:伟大的科学家年轻时多半是小鲜肉)
所以从贡献量看来,费希尔着实是当之无愧的现代统计学之父。自古奇才多传奇,属于费希尔的传奇不仅仅体现在他的高颜值,更体现在他和其他几位统计界大牛的相互争论当中。高手相争,路人即使站在一旁观战也能受益匪浅,那么我们来感受一下高手相争到底是怎样的场面。
和皮尔逊互怼极大似然估计vs矩估计
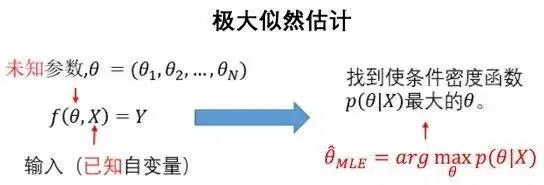
关于参数估计,一些读者会首先想到费希尔的极大似然估计(Max Likelihood Estimation, MLE)。这种参数估计的方法既运算简便又易于数学分析,还能为如今红透半边天的贝叶斯理论与统计学习理论,实在是数理统计领域的镇海之宝。极大似然估计的粗略定义见下图:
在极大似然估计提出(1912年)之前不久,皮尔逊提出了分布族理论(1894年),并以此提出矩估计(Moment Estimation):
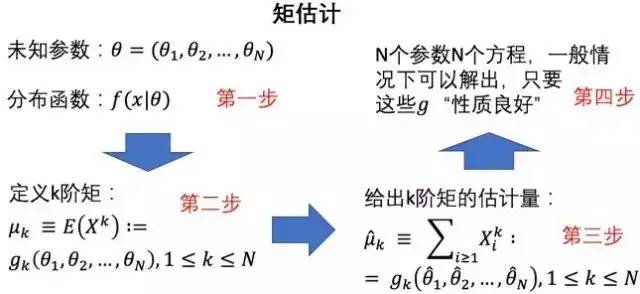
所谓性质良好,用数学语言表示就是,g在θ的真实值处是个局部微分同胚(雅可比矩阵非退化)。所以无论从定义还是计算量看来,矩估计都比极大似然估计麻烦了不少,这也是为什么今天在参数估计中,我们很少运用矩估计方法。
但当时皮尔逊已然是英国统计学界的泰斗级人物,费希尔年方22岁,只是小鲜肉一枚。小鲜肉刚开始时还和皮尔逊保持着良好的关系,但随着费希尔信息量、充分统计量、自由度理论等概念的提出,小鲜肉感觉已经有了自立门户的底气,便开始发表文章以批评皮尔逊的矩法(1916年)。这场争论一直持续到1936年,皮尔逊去世,才告一段落[1]。
从结果看来,费希尔似乎取得了这场争论的胜利,因为如今极大似然估计的名气比矩估计高很多。但根据已故统计学院士陈希孺先生的观点,由于极大似然估计在非参数估计领域基本不适用,从这点看来矩估计也有着自身的优点[1]。

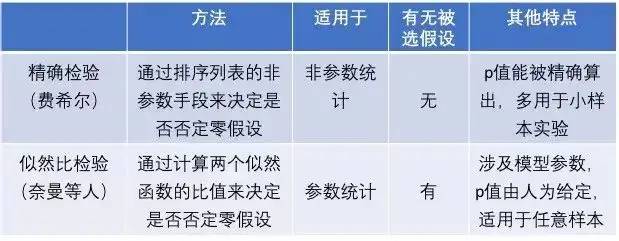
和奈曼互怼精确检验vs似然比检验
假设检验和参数估计并称数理统计的两大基础分支,现在我们把话题从参数估计转到假设检验上。
什么是假设检验呢?简单地讲,假设检验不外乎就是找寻一种方法来验证某个观点正确与否,而这个目的预示着这两大基础分支在数学上的区别参数估计问题在数学上能够被良好地定义出来,而假设检验则缺乏严格的数学定义。正是这个原因导致了费希尔和奈曼等人在假设检验的数学定义上的分歧。
我们先来看看两种理解的区别:
依照惯例,零假设(Null Hypothesis)一般指希望被验证或推翻的论述,备选假设(Alternative Hypothesis)是指和零假设平行的,在零假设被否定以后所要接受的结论;两者就好像参加选美比赛决赛一样,非此即彼。值得注意的是,零假设和备选假设的选取都有很强的主观性,其定义在数学上并不严格,这是统计学和数学思想的一个重大差别。
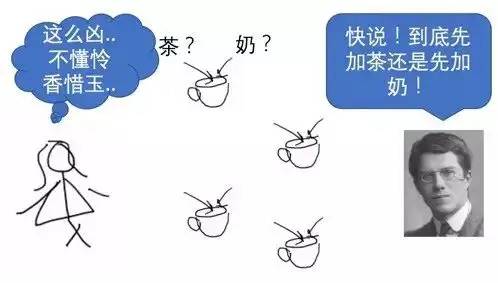
尽管今天统计学课本上的假设检验大都是基于奈曼及其合作者的似然比检验(Likelihood Ratio Test)来定义的,而非费希尔的精确检验(Exact Test)。但值得一提的是,费希尔的思想源于一个很简单的实验女士品茶实验(Lady Taste Tea )[5]。费希尔的一位女性朋友号称自己能够品尝出一杯奶茶到底是先加奶还是先加茶(英国人喝茶都喜欢加奶,但和台湾奶茶不同),费希尔自然不信,于是调制了八杯茶,任意选取其中四杯让该女士品尝。这个实验里的零假设是该女士没有辨别奶和茶添加次序的能力,由于样本(茶)数量有限,若零假设成立,那么女士胡乱猜对答案的概率可用简单的排列组合计算出来;若这个概率太低,费希尔就不得不推翻零假设,承认该女士的味觉确实超人一等。
诚然,似然比检验比精确检验更适用于数学分析,应用面也更广,不过读者们不要小看上面这个简单的实验。这个实验不仅诱使费希尔提出精确检验的基本原理,同时还帮助他给出的p值的定义,而p值则是检验某一假设是否成立的重要手段。从女士品茶的实验中我们还可以看出,费希尔不仅是统计学家,更是一位出色的实验科学家,他很善于把实验和抽象的数学理论联系起来,这点非常难能可贵。
除了p值,假设的检验方法还有很多,例如基于似然比检验的功效函数(Power Function)法,运筹学中常用的损失函数(Loss Function)法等。每种方法都有不同的适用情景,也体现着不同科学家对同一问题的不同理解,详情可参考文献[6]。
慧眼识哥色特万能的自由度理论
接连怼过两位同时代的数理统计大牛后,费希尔表示有些累了。幸好费希尔和另一位大牛,哥色特,一直保持着良好的关系(事实上哥色特为人非常和善,和所有人都能维持友谊)。
统计学三大分布中的t分布和F分布、方差分析(ANOVA)和线性判别分析(Linear Discriminant Analysis)都是现代统计学中非常重要的概念,而他们都是费希尔的成果。费希尔之所以能串联这么多看似不同的分支,归根结底是源于他的自由度(Degree of Freedom)思想。
体现自由度思想的第一个例子是t分布。事实上t分布最初是由哥色特(笔名叫student)提出的,哥色特发现,当观测样本取自于同一个均值和方差都未知的正态分布时,这些样本经标准化处理(中心化和归一化)后不再服从正态分布,而是服从t分布。当样本数量很大时,正态分布和t分布相差无几,但在小样本情形下有不可忽视的差异。
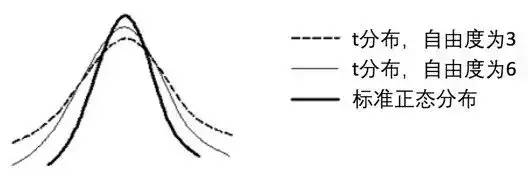
哥色特提出t分布时并没引起统计泰斗皮尔逊的重视,因为皮尔逊并不认可当时尚处于萌芽期的小样本统计理论。不过当费希尔却和哥色特一拍即合,继而把t分布发扬光大。为什么正态分布样本经标准化处理以后就不一定符合正态分布呢?根本原因在于,当正态分布的均值和方差都未知时,样本均值和样本方差并不独立,因为中心化以后都样本满足限制条件:
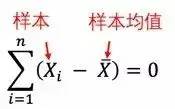
如果我们一共取了n个样本,那么由于以上限制条件,样本均值和样本方差所对应的自由度就要少一个,变成了n-1。这就是为什么人们在计算样本方差时,应当除以n-1而不是样本总量n。
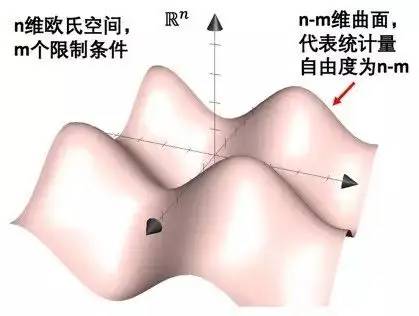
也许到这里,很多读者会惊叹于费希尔的智慧:这么深刻的自由度概念,他是怎么想到的啊?事实上这应该归结于费希尔深厚的几何功底,在他早期与哥色特的通信中我们可以看到,费希尔一直都在用流形(曲面)的观点描述抽样问题[1]。具体说来,他把n个样本看作n维欧氏空间的一个n维向量,如果限制条件有m个,那么这m个条件加起来就组成了n维空间中的n-m维曲面,因此对应统计量的自由度就是n-m。用几何观点看待统计问题,往往更为本质而直观,我在另一篇文章《大数据时代,参数怎么降维?》(传送门)中有更详细的案例。
自由度理论的集大成者,是费希尔所提出的F分布以及方差分析,这两个概念直接奠定了现代实验设计理论的理论基础[5]。后人根据费希尔的思想,在回归分析中给出了自由度的严格数学定义[7];另一些学者则延续了费希尔的几何观点,把统计中的重要概念用微分几何的语言描述一遍,产生了许多新奇而有趣的观点,例如[8]。
此外,费希尔根据方差分析法提出的线形判别分析(Linear discriminant analysis)也许是第一个解决分类问题的方法,但随着上世纪九十年代统计学习理论的突然流行,今天我们所熟悉的方法主要是计算效率更高的支持向量机(Support Vector Machine)、神经网络(Neural Network)、决策树(Decision Tree)和贝叶斯方法等。不过线性判别分析在数理统计领域依然有着宝贵的科研价值。
不仅仅是现代统计学之父
到这里,大家已经对费希尔在统计和实验科学领域的贡献有了大致了解。相信很多读者对费希尔在统计学中的贡献有了深刻印象。
但费希尔的贡献还远不止于此!事实上不为人知的是,费希尔其实还是一名伟大的生物学家,他引用量最高的著作叫做《自然选择的基因理论》(The Genetical Theory of Natural Selection),也是进化生物学中最具影响力的著作之一。费希尔从数学的观点出发,把达尔文的进化论和孟德尔的遗传学理论联系了起来,从中创立了种群基因学(Polulation Genetics)这一全新领域,还对现代心理学和农业科学的发展做出了非常深刻的贡献。著名进化论学家理查德·道金斯(《自私的基因》一书作者)甚至称他为达尔文之后最伟大的生物学家[2]。
作为这么一位几乎以一人之力建立了现代统计基础的全才,为什么他的名气始终比不上爱因斯坦、冯诺伊曼、居里夫人等同时代的顶尖科学家呢?我猜测,原因有以下几点:
- 由于当时统计学并不属于正式的基础科学,所以尽管费希尔对后世的影响并不逊于任何顶尖科学家,在讨论最伟大的科学家时,他经常被忽略;
- 获奖不多,和诸位诺奖菲尔兹奖获得者没法比较;
- 尽管对生物学的发展有着巨大影响,但他的生物学家身份被统计学冲淡了,在谈到生物学时似乎很少有人会提及这位现代统计学之父。
或许评价一个科学家所做的贡献,还得交给时间去完成。无论如何,我很期待费希尔能够获得与他贡献值相匹配的名气。
又或许,费希尔名气不大的另一个原因是,他曾试图用自己的理论证明吸烟不会影响健康[9]。毕竟他自己就是一位香烟爱好者。

你的意见如何呢?欢迎大家畅所欲言!
参考文献
[1] 陈希孺,《数理统计学简史》。
[2] https://en.wikipedia.org/wiki/Ronald_Fisher.
[3] http://www.dailymail.co.uk/sciencetech/article-2002163/1927-Solvay-Conference-Electrons-Photons-Is-greatest-meeting-minds-ever.html.
[4] C.R. Rao, Statistics And Truth: Putting Chance To Work.
[5] Ronald Fisher, The Design of Experiments.
[6] George Casella and Roger L. Berger, Statistical Inference.
[7] Raymond H. Myers, Classical and Modern Regression with Applications.
[8] S. Amari, Information Geometry and Its Applications.
[9] Paul D. Stolley, When Genius Errs: R. A. Fisher and the Lung Cancer Controversy.
来源:科普最前线
作者:sd_equation
编辑:怀疑探索者
本站涵盖的内容、图片、视频等数据系网络收集,部分未能与原作者取得联系。若涉及版权问题,请联系我们删除!联系邮箱:ynstorm@foxmail.com 谢谢支持!
现代统计学之父
或许对于大部分读者而言,罗纳德・费希尔(Ronald Fisher)并不算出名,但有数理统计基础的读者会对他有所耳闻。费希尔信息量、费希尔z分布、费希尔变换(相关系数的定义)等等,都是他的创造。其实他的贡献远不止此现代统计学之父这一称号,是对他更为贴切的描述。
费希尔出生于1890年,活跃于20世纪初[2]。很多读者都知道,这个时代可以算是人才辈出、百家争鸣,各个学科都得到了突飞猛进的发展,牛顿伽利略那个少数人掌管科学界的情况早已如同过往云烟。下面这张号称科学界最牛合影的照片拍摄于1927年,也仅仅包含了当时全球三分之一左右的智囊[3]。
(解图:第五届索尔维会议,组织者为普朗克,但主要是哥本哈根学派和爱因斯坦等人关于量子物理的争端)
尽管费希尔的名声可能不及上面各路大牛,但至少在现代统计学界,他依然是执牛耳者。其实那个年代著名的统计学家也不少,为什么费希尔才是现代统计学之父呢?我们来看看和费希尔同时代并且齐名的几位统计学家的主要贡献:
再来看看费希尔(不包括本文开头的几项贡献):
(怀疑探索者按:胡子一剃我们就可以得出结论:伟大的科学家年轻时多半是小鲜肉)
所以从贡献量看来,费希尔着实是当之无愧的现代统计学之父。自古奇才多传奇,属于费希尔的传奇不仅仅体现在他的高颜值,更体现在他和其他几位统计界大牛的相互争论当中。高手相争,路人即使站在一旁观战也能受益匪浅,那么我们来感受一下高手相争到底是怎样的场面。
和皮尔逊互怼极大似然估计vs矩估计
关于参数估计,一些读者会首先想到费希尔的极大似然估计(Max Likelihood Estimation, MLE)。这种参数估计的方法既运算简便又易于数学分析,还能为如今红透半边天的贝叶斯理论与统计学习理论,实在是数理统计领域的镇海之宝。极大似然估计的粗略定义见下图:
在极大似然估计提出(1912年)之前不久,皮尔逊提出了分布族理论(1894年),并以此提出矩估计(Moment Estimation):
所谓性质良好,用数学语言表示就是,g在θ的真实值处是个局部微分同胚(雅可比矩阵非退化)。所以无论从定义还是计算量看来,矩估计都比极大似然估计麻烦了不少,这也是为什么今天在参数估计中,我们很少运用矩估计方法。
但当时皮尔逊已然是英国统计学界的泰斗级人物,费希尔年方22岁,只是小鲜肉一枚。小鲜肉刚开始时还和皮尔逊保持着良好的关系,但随着费希尔信息量、充分统计量、自由度理论等概念的提出,小鲜肉感觉已经有了自立门户的底气,便开始发表文章以批评皮尔逊的矩法(1916年)。这场争论一直持续到1936年,皮尔逊去世,才告一段落[1]。
从结果看来,费希尔似乎取得了这场争论的胜利,因为如今极大似然估计的名气比矩估计高很多。但根据已故统计学院士陈希孺先生的观点,由于极大似然估计在非参数估计领域基本不适用,从这点看来矩估计也有着自身的优点[1]。
和奈曼互怼精确检验vs似然比检验
假设检验和参数估计并称数理统计的两大基础分支,现在我们把话题从参数估计转到假设检验上。
什么是假设检验呢?简单地讲,假设检验不外乎就是找寻一种方法来验证某个观点正确与否,而这个目的预示着这两大基础分支在数学上的区别参数估计问题在数学上能够被良好地定义出来,而假设检验则缺乏严格的数学定义。正是这个原因导致了费希尔和奈曼等人在假设检验的数学定义上的分歧。
我们先来看看两种理解的区别:
依照惯例,零假设(Null Hypothesis)一般指希望被验证或推翻的论述,备选假设(Alternative Hypothesis)是指和零假设平行的,在零假设被否定以后所要接受的结论;两者就好像参加选美比赛决赛一样,非此即彼。值得注意的是,零假设和备选假设的选取都有很强的主观性,其定义在数学上并不严格,这是统计学和数学思想的一个重大差别。
尽管今天统计学课本上的假设检验大都是基于奈曼及其合作者的似然比检验(Likelihood Ratio Test)来定义的,而非费希尔的精确检验(Exact Test)。但值得一提的是,费希尔的思想源于一个很简单的实验女士品茶实验(Lady Taste Tea )[5]。费希尔的一位女性朋友号称自己能够品尝出一杯奶茶到底是先加奶还是先加茶(英国人喝茶都喜欢加奶,但和台湾奶茶不同),费希尔自然不信,于是调制了八杯茶,任意选取其中四杯让该女士品尝。这个实验里的零假设是该女士没有辨别奶和茶添加次序的能力,由于样本(茶)数量有限,若零假设成立,那么女士胡乱猜对答案的概率可用简单的排列组合计算出来;若这个概率太低,费希尔就不得不推翻零假设,承认该女士的味觉确实超人一等。
诚然,似然比检验比精确检验更适用于数学分析,应用面也更广,不过读者们不要小看上面这个简单的实验。这个实验不仅诱使费希尔提出精确检验的基本原理,同时还帮助他给出的p值的定义,而p值则是检验某一假设是否成立的重要手段。从女士品茶的实验中我们还可以看出,费希尔不仅是统计学家,更是一位出色的实验科学家,他很善于把实验和抽象的数学理论联系起来,这点非常难能可贵。
除了p值,假设的检验方法还有很多,例如基于似然比检验的功效函数(Power Function)法,运筹学中常用的损失函数(Loss Function)法等。每种方法都有不同的适用情景,也体现着不同科学家对同一问题的不同理解,详情可参考文献[6]。
慧眼识哥色特万能的自由度理论
接连怼过两位同时代的数理统计大牛后,费希尔表示有些累了。幸好费希尔和另一位大牛,哥色特,一直保持着良好的关系(事实上哥色特为人非常和善,和所有人都能维持友谊)。
统计学三大分布中的t分布和F分布、方差分析(ANOVA)和线性判别分析(Linear Discriminant Analysis)都是现代统计学中非常重要的概念,而他们都是费希尔的成果。费希尔之所以能串联这么多看似不同的分支,归根结底是源于他的自由度(Degree of Freedom)思想。
体现自由度思想的第一个例子是t分布。事实上t分布最初是由哥色特(笔名叫student)提出的,哥色特发现,当观测样本取自于同一个均值和方差都未知的正态分布时,这些样本经标准化处理(中心化和归一化)后不再服从正态分布,而是服从t分布。当样本数量很大时,正态分布和t分布相差无几,但在小样本情形下有不可忽视的差异。
哥色特提出t分布时并没引起统计泰斗皮尔逊的重视,因为皮尔逊并不认可当时尚处于萌芽期的小样本统计理论。不过当费希尔却和哥色特一拍即合,继而把t分布发扬光大。为什么正态分布样本经标准化处理以后就不一定符合正态分布呢?根本原因在于,当正态分布的均值和方差都未知时,样本均值和样本方差并不独立,因为中心化以后都样本满足限制条件:
如果我们一共取了n个样本,那么由于以上限制条件,样本均值和样本方差所对应的自由度就要少一个,变成了n-1。这就是为什么人们在计算样本方差时,应当除以n-1而不是样本总量n。
也许到这里,很多读者会惊叹于费希尔的智慧:这么深刻的自由度概念,他是怎么想到的啊?事实上这应该归结于费希尔深厚的几何功底,在他早期与哥色特的通信中我们可以看到,费希尔一直都在用流形(曲面)的观点描述抽样问题[1]。具体说来,他把n个样本看作n维欧氏空间的一个n维向量,如果限制条件有m个,那么这m个条件加起来就组成了n维空间中的n-m维曲面,因此对应统计量的自由度就是n-m。用几何观点看待统计问题,往往更为本质而直观,我在另一篇文章《大数据时代,参数怎么降维?》(传送门)中有更详细的案例。
自由度理论的集大成者,是费希尔所提出的F分布以及方差分析,这两个概念直接奠定了现代实验设计理论的理论基础[5]。后人根据费希尔的思想,在回归分析中给出了自由度的严格数学定义[7];另一些学者则延续了费希尔的几何观点,把统计中的重要概念用微分几何的语言描述一遍,产生了许多新奇而有趣的观点,例如[8]。
此外,费希尔根据方差分析法提出的线形判别分析(Linear discriminant analysis)也许是第一个解决分类问题的方法,但随着上世纪九十年代统计学习理论的突然流行,今天我们所熟悉的方法主要是计算效率更高的支持向量机(Support Vector Machine)、神经网络(Neural Network)、决策树(Decision Tree)和贝叶斯方法等。不过线性判别分析在数理统计领域依然有着宝贵的科研价值。
不仅仅是现代统计学之父
到这里,大家已经对费希尔在统计和实验科学领域的贡献有了大致了解。相信很多读者对费希尔在统计学中的贡献有了深刻印象。
但费希尔的贡献还远不止于此!事实上不为人知的是,费希尔其实还是一名伟大的生物学家,他引用量最高的著作叫做《自然选择的基因理论》(The Genetical Theory of Natural Selection),也是进化生物学中最具影响力的著作之一。费希尔从数学的观点出发,把达尔文的进化论和孟德尔的遗传学理论联系了起来,从中创立了种群基因学(Polulation Genetics)这一全新领域,还对现代心理学和农业科学的发展做出了非常深刻的贡献。著名进化论学家理查德·道金斯(《自私的基因》一书作者)甚至称他为达尔文之后最伟大的生物学家[2]。
作为这么一位几乎以一人之力建立了现代统计基础的全才,为什么他的名气始终比不上爱因斯坦、冯诺伊曼、居里夫人等同时代的顶尖科学家呢?我猜测,原因有以下几点:
- 由于当时统计学并不属于正式的基础科学,所以尽管费希尔对后世的影响并不逊于任何顶尖科学家,在讨论最伟大的科学家时,他经常被忽略;
- 获奖不多,和诸位诺奖菲尔兹奖获得者没法比较;
- 尽管对生物学的发展有着巨大影响,但他的生物学家身份被统计学冲淡了,在谈到生物学时似乎很少有人会提及这位现代统计学之父。
或许评价一个科学家所做的贡献,还得交给时间去完成。无论如何,我很期待费希尔能够获得与他贡献值相匹配的名气。
又或许,费希尔名气不大的另一个原因是,他曾试图用自己的理论证明吸烟不会影响健康[9]。毕竟他自己就是一位香烟爱好者。
你的意见如何呢?欢迎大家畅所欲言!
参考文献
[1] 陈希孺,《数理统计学简史》。
[2] https://en.wikipedia.org/wiki/Ronald_Fisher.
[3] http://www.dailymail.co.uk/sciencetech/article-2002163/1927-Solvay-Conference-Electrons-Photons-Is-greatest-meeting-minds-ever.html.
[4] C.R. Rao, Statistics And Truth: Putting Chance To Work.
[5] Ronald Fisher, The Design of Experiments.
[6] George Casella and Roger L. Berger, Statistical Inference.
[7] Raymond H. Myers, Classical and Modern Regression with Applications.
[8] S. Amari, Information Geometry and Its Applications.
[9] Paul D. Stolley, When Genius Errs: R. A. Fisher and the Lung Cancer Controversy.
来源:科普最前线
作者:sd_equation
编辑:怀疑探索者
本站涵盖的内容、图片、视频等数据系网络收集,部分未能与原作者取得联系。若涉及版权问题,请联系我们删除!联系邮箱:ynstorm@foxmail.com 谢谢支持!









